
Когда необходимо принять решение по поводу двух или более групп и узнать, какие переменные их различают, то используют линейный дискриминантный анализ. Также дополнительно применяют объединенный с данной системой линейный дискриминант Фишера (ЛДА).
Система использует статистические методы, объединив их с машинным обучением, чтобы получить более точный результат. Результаты, как правило, применяют для создания линейного классификатора. Кроме того, с помощью LDA можно сократить размерность пространства, состоящего из признаков, перед следующей классификацией.
Метод напрямую связан с эквивалентными регрессионным и дисперсионным анализом, которые выдают результат похожего вида, где надо выявить зависимость между линейными комбинациями каких-либо данных. Однако есть определенная разница между этими методиками. У Linear Discriminant Analysis величина номинальная, у двух перечисленных анализов – численная. Также можно найти схожие особенности между ЛДА, методом главных компонент и анализом факторов.
Стоит заметить, что нужно использовать непрерывные величины, если же применяются другие виды, то больше подходят другие модели вычисления.
Алгоритм анализа данных использует следующие понятия при работе:
- каноническая дискриминантная величина;
- логистическая регрессия, получающаяся при вычислении;
- расчет переменных линейной цепи, которые получаются при распределении информации.
Линейно-дискриминантный способ находит применение в различных областях. Нередко его можно встретить при маркетинговых исследованиях, в управлении производством товара и т.д. Современные data mining позволяют решать довольно интересные задачи, например, линейный анализ может пригодиться при распознавании лиц. В маркетинге метод используется для формирования задачи и сбора данных, оценки дискриминантной функции, отображения двумерного изображения.
Задачи и методы анализа данных через дискриминант Фишера
С помощью данного метода можно вычислять задачи машинного обучения, используя статистический или байесовский подход. Также определять расстояние между двумя разными группами исследуемых объектов или событий. В целом решает практически те же самые задачи, что и ЛДА. Например, выполняет распознавание лиц (фишеровские лица).
Стоит заметить, что статистический метод измерения подводит пользователей к линейным дискриминантам. Именно под данными эквивалентными преобразованиями понимают метод Фишера. Это при условии, что используются следующие гипотезы:
- базовые от байесовского классификатора;
- каждый класс распределяется по нормальным законам;
- матрицы ковариаций каждого класса равны.
Данные методы анализа используют, чтобы получить стабильные алгоритмы классификации. Особенно обозначенным анализом процессов удобно пользоваться, если не хватает данных, нужных для обучения. Отлично система подходит для решения простых задач по классификации, в частности, в случаях, когда каждый класс похож друг на друга. Тогда прогноз получается значительно точнее.
Сервис для автоматизации анализа LDA с применением технологий Data Mining
Наш сервис предлагает простые способы использования данного анализа. Клиентам потребуется только загрузить информацию в нужном формате, чтобы система провела быстрый расчет. Вся информация подается в виде схемы, которую также можно визуализировать.
При создании программы использовались современные технологии, которые позволяют сделать сложные вычисления намного быстрее и проще. Все предположения отличаются высоким уровнем достоверности, поэтому пользователи могут точно определить то, что им нужно.
Сервис можно использовать для решения совершенно разных задач:
- Применяя различные параметры, можно сделать исследование в сфере образования. К примеру, условный ученый хочет вычислить, к какой категории соотносится школьник: поступающий в колледж, в специализированную школу или отказывающийся от дальнейшего образования. Таким образом, можно узнать, какой путь для выпускника наиболее благоприятный.
- Нередко система применяется в медицине. Врач с помощью метода считывает характеристику пациента, после чего может сделать вывод, больной выздоровеет, частично выздоровеет или нет.
- В сфере биологии. Он позволяет провести анализ функции, помогающий определить типы и группы растений, животных и т. д., распределить их по классам.
- Достаточно легко проводить какую-либо статистику. Например, чтобы вычислить средний рост мужчин и женщин по определенному региону. Система отобразит разницу между представителями разного пола, учтет средние показатели среди всех испытуемых.
- Часто применяется для решения задач в промышленности. Можно вычислить частотный сигнал какого-либо устройства, на каких настройках работа производится лучше, узнать силу воздействия и т.д.
Прогнозирование получается довольно точным. Притом операторный вклад здесь минимален, нужно только выставить критерии, необходимые для вычисления определенных групп данных.
Примеры использования сервиса
Чтобы нашим клиентам был понятен принцип работы, нужно рассмотреть данный пример. Предлагаем ознакомиться с пошаговой инструкцией.
Пользователям потребуется загрузить файл в нужном формате с набором данных, в котором также определяют свойства выборки:
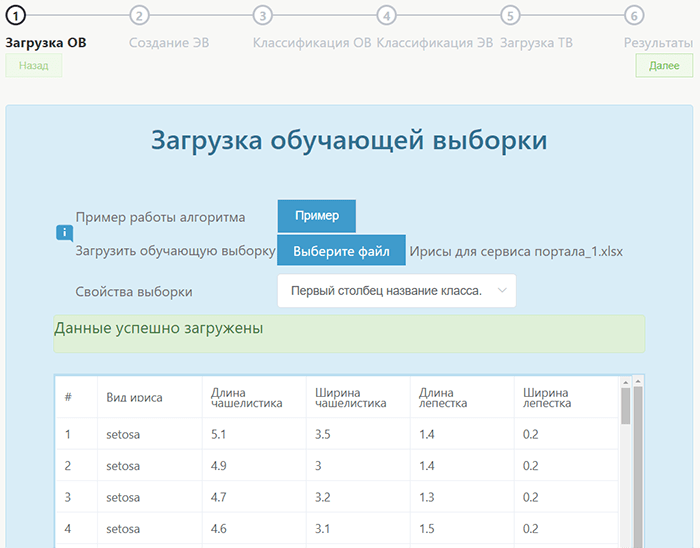
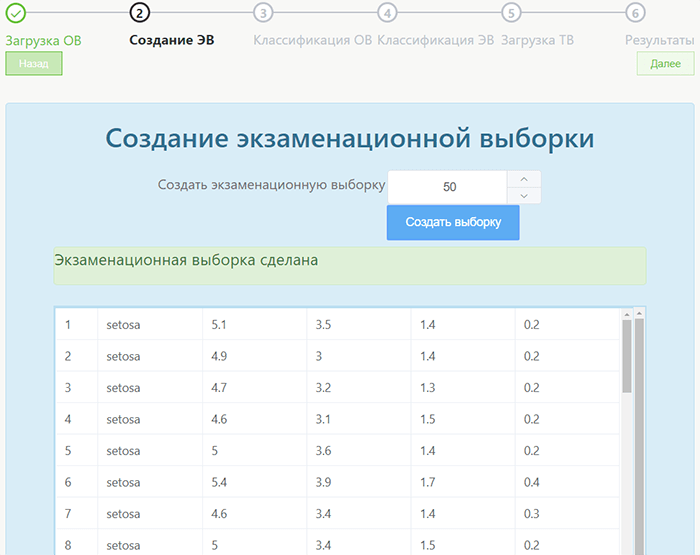
Далее необходимо создать экзаменационную выборку. Пользователи отдают предпочтение нужному значению, руководствуясь желаемым результатом.
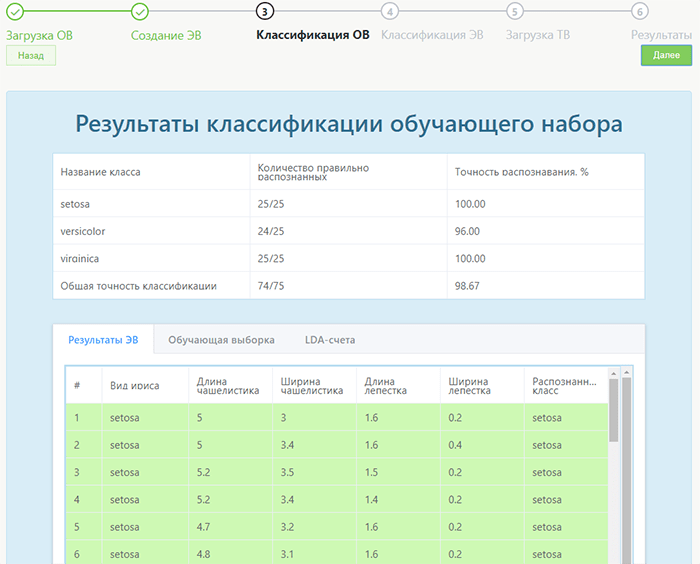
Далее производится систематизация обучающего набора. По результатам можно увидеть точность классификации, показанную в процентах, а также количество распознанных и пропущенных данных.
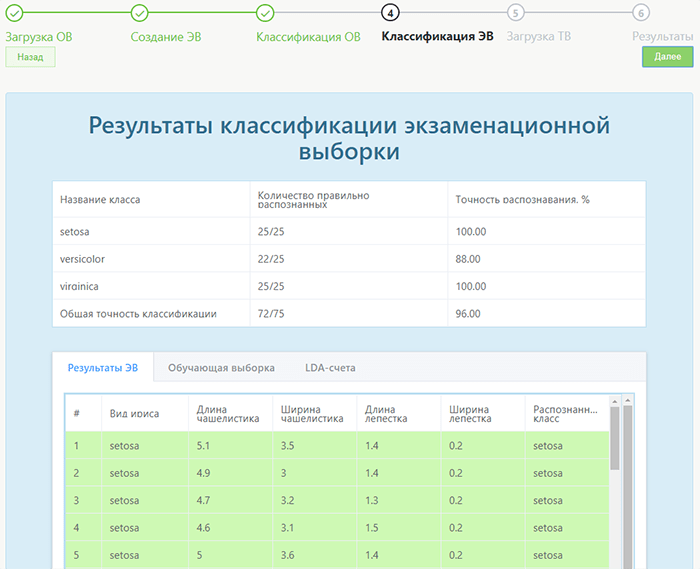
После чего можно приступать к классификации экзаменационной выборки. Пользователи снова увидят в процентном соотношении уровень достоверности и количество распознанных показателей.
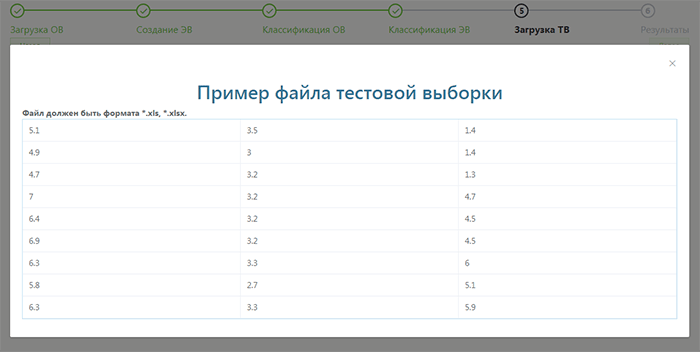
По завершении данных работ производится тестовая выборка. Файл должен выглядеть следующим образом, чтобы считать результаты.
В заключение пользователи получают окончательный результат. Система оценивает полученные данные анализируемой задачи. Используя метод, можно узнать распределения вероятности или другие сведения.