

В процессе решения задач различной сложности и спецификации, необходимо провести правильный анализ данных. Это связано с тем, что объемы вычисления достаточно велики, а нейронная сеть, что выполняет работу, имеет ограниченный диапазон чисел и возможных операций, что может сказаться на точности результата.
Поэтому проводится предварительная обработка данных, которая упрощает анализ и помогает очистить информацию от лишнего, используя нейросети и машинное обучение.
Процедура включает следующие этапы:
- производится масштабирование данных, когда значение компонентов заключается в определенный диапазон;
- далее происходит нормировка, в этом случае устанавливаются ограничения на разброс случайных величин;
- последний этап включает факторный анализ, где исключают несущественные данные.
Таким образом, в data mining избегают недопустимых значений или комбинаций.
Описание процесса обработки информации и его задачи
В предварительной обработке данных используют принцип «мусор на входе – мусор на выходе». Лишняя информация и «шумные» данные усложняют извлечение необходимого в процессе machine learning. Тренировка сопрягается с различными затруднениями, поэтому подготовка с последующей фильтрацией занимают немало времени. Предобработка данных начинается с подготовки, которая включает:
- очистку информации;
- отбор нужных экземпляров;
- приведение данных в нормальную форму;
- преобразования;
- выделение и последующий отбор признаков.
В результате получается набор для тренировок машины, который впоследствии упрощает задачу и способствует обучению вычислительной техники. Подобная работа, включающая сбор и предварительную обработку информации, очистку данных и т.д. может использоваться нейросетями или для ручной обработки.
Используются данные методы в следующих разделах анализа:
- вычисление базовых характеристик, например, в центральных моментах;
- проверка основных гипотез, чаще всего симметричность или однородность;
- проверка для стохастичности приведенной выборки;
- исключение аномальных исследований;
- для разведочного анализа.
Это помогает избежать ошибки в самых различных областях. Так, например, можно использовать предварительную подготовку данных при исследованиях в следующих сферах: геофизических, экономических, биологических, медицинских и т.д. Технологический процесс используется при разборке результатов лазерного сканирования, медицинских тестов, выделения общих или различных признаков каких-либо исследуемых объектов и т.д.
Самые популярные примеры ошибок, которые метод позволяет исключить, это:
- доход, уходящий в отрицательное значение;
- положительный тест на беременность для мужчины.
Поэтому качественные вычисления возможны с помощью обозначенных методов обработки.
Сервис предварительной обработки данных
Командой специалистов был разработан сервис, помогающий исключить или значительно уменьшить некорректность в вычислениях. Инструменты были созданы с помощью точных расчетов, позволяющих использовать различные методы исследования.
Воспользовавшись услугами, можно решить следующие задачи:
- Обнаружить различные ошибки, а именно неверную информацию в упорядоченных и неупорядоченных показателях, выявить всевозможные аномалии или противоречия.
- Исправить представленные ошибки. Технические средства позволяют сразу же заполнить места пропусков, а также отредактировать выявленные аномалии и противоречия.
В результате доступен просмотр внесенных измерений, что помогает лучше понять особенности работы.
Как правило, применяются следующие программные методы:
- Производится очистка, которая в свою очередь представляет собой процесс выявления и коррекции или исключения записей с ошибками.
- Приведение информации в нормальную форму, чтобы стандартизировать диапазон с поданными значениями, где фигурируют независимые переменные, а также признаки. Подается в определенных интервалах.
- Преобразование – данные приводятся в формате, который необходим пользователю.
- Выделение признаков, в ходе чего преобразуются входные показатели в один набор.
- Уплотнение – процесс преобразования числовых показателей в упорядоченный и понятный пользователю вид. Таким образом, уменьшается количество и размерность информации.
В ходе реализации выявляются различные виды ошибок: противоречивость, неполнота, неправдоподобие, опечатки, несоответствие форматов, дублирование.
Удобный интерфейс позволяет быстро и без особых проблем разобраться в особенностях программы. Помимо этого, предоставляем доступ к моделированию полученных потоков с помощью другой программы, доступной на сайте. Кроме того, регистрация и оплата не требуются – работаем совершенно бесплатно. Сохранить выводы можно в любом удобном хранилище.
Однако заметим, что глубокая очистка мало возможна в некоторых случаях, так как требуется заранее предусмотреть ограничения на поиск ошибок с последующим устранением, а также с выявлением закономерностей. Впрочем, для уточнения результатов можно воспользоваться другими программами сервиса, которые демонстрируют поразительную эффективность.
Примеры использования инструмента
Чтобы лучше понимать принцип работы сервиса, предлагаем ознакомиться с примером использования.
Давайте рассмотрим алгоритм с помощью загруженного файла в нужном формате. После этого, пользователь выбирает те особенности, которые ему нужно проверить. Достаточно поставить «галочку» напротив требуемых обозначений. Например, заменить пропуски по столбцу или другим способом.
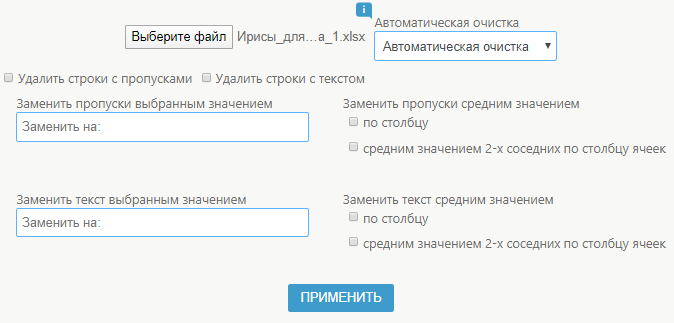
Можно выбрать автоматическую очистку или разбиение выборки.
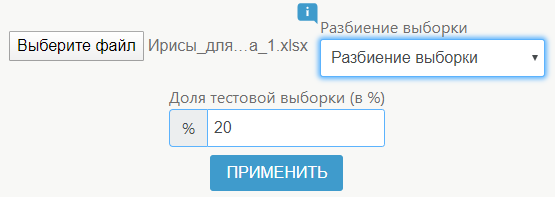
В результате пользователь получает файл в аналогичном загруженному формате, где представлены полученные данные:
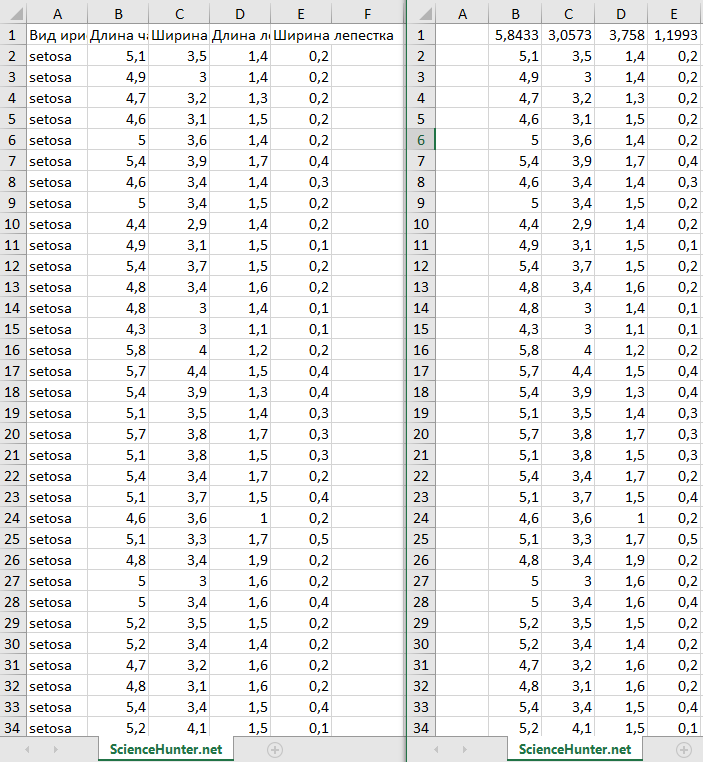
Изображения демонстрируют разницу между функциями с «галочкой», отсутствующей или проставленной, на поле со столбцами.