

Распознающие или решающие деревья – это метод классификации данных, который появился благодаря активному развитию технологий. Данный способ помогает крупным предприятиям хранить и обрабатывать информацию в больших объемах, при этом проводить анализ стало еще удобнее. Систему характеризует полная автоматизация, что позволят оперативно проводить операции.
Этот способ обработки важной информации был разработан Карлом Ховландом – американским психологом, и Эрлом Б. Хантом, его коллегой, который специализировался на изучении человеческого и искусственного интеллекта. Ученые работали вместе в конце 50-х годов ХХ века и изучали модели данных. Однако решающей стала совместная работа Ханта с Мэрином и Стоуном, которая увидела свет в 1966 году. Ученые ближе продвинулись к кодированию файлов.
Система в виде дерева решений значительно облегчила работу специалистов, которые обрабатывали большие объемы документов. Теперь можно было не делать это вручную, а пользоваться алгоритмами.
Особенности практического применения
системы классификации информации
Полезность автоматизированных программных сервисов доказана широкой сферой применения. Задачи, которые решаются моделью, можно объединить в три широких класса:
- Описание данных – деревья позволяют хранить полученные знания в удобном формате. Получаемая схема содержит точные описания каждого объекта.
- Позволяет классифицировать данные. Объекты будут соотнесены один к другому по уже известным классам.
- Регрессия. Когда целевые переменные обладают непрерывным значением, система позволяет установить, какая наблюдается зависимость главной переменной от входных данных.
Благодаря такому способу работы можно применять распознающие деревья в областях информационной безопасности, корпоративной работы с клиентами, построения многомерного пространства для различных научных исследований и области информатики.
Например, они успешно используются:
- В банковском деле – помогают оценить кредитоспособность клиента, который желает взять ссуду.
- В промышленности – позволяют определить характеристики качественной продукции, выявить дефекты, провести эксперимент без нарушения целостности объекта (качество сварки и т. п.).
- В медицине – помогают диагностировать заболевание на основе взаимосвязи симптомов.
- В молекулярной биологии – позволяют провести анализ строения аминокислот и т. д.
В целом классификатор можно применить практически в любой сфере, где необходимо установить первичный поток, обеспечить защиту информации и пр.
Описание системы классификации информации
Наш сервис представляет собой ресурс, который позволяет быстро и просто использовать методы классификации данных, включая деревья решений. Мы гарантируем каждому клиенту конфиденциальность персональных данных. На сайте предлагается загрузить всю необходимую информацию, по которой уже идет постановка задачи.
Но для начала стоит разобраться в том, что собой представляют «решающие деревья». Они воспроизводят логические схемы, которые позволяют получить конечный ответ об объектах классификации. Анализ построен на иерархии и последовательности структур. Это похоже на принципы в ботанике и биологии, когда данные идут один за другим, чтобы задать вопрос к следующему объекту, нужно получить ответ на предыдущий.
Используя компьютер и современные data mining технологии, можно построить модели с помощью опорных векторов, которые помогут найти нужную информацию. Алгоритм действий:
- загрузить файлы на наш сервис;
- дождаться выполнения предобработки данных;
- дальше система кодирования информации разделит их на ОВ и ЭВ;
- после чего происходит комбинация классификационных признаков;
- протестировать работу.
Весь процесс выполняется быстро и просто, сервис даст необходимые подсказки, чтобы провести классификацию данных.
Веб-сервис распознает объект, руководствуясь последовательностью сравнений значений прилагающихся признаков, соотнося их с константами на равенство или неравенство. В результате представления данных получается двоичное дерево. Используются различные индексы, например, индекс ошибочной классификации Джини, которые могут усовершенствовать работу информационных технологий.
Примеры построения моделей данных при помощи системы обработки и классификации
Выделяют различные образцы построения информационного доступа к всевозможным системам. Наш сервис предлагает выполнить данную процедуру без каких-либо сложностей.
Использование сайта отличается множеством достоинств:
- быстрый процесс обучения;
- извлечение правил на естественном языке;
- user-friendly система, которая понятна простым пользователям;
- генерирование набора правил даже в тех областях, где пользователю сложно формализовать данные;
- высокая точность прогноза, более качественно сопоставляет понятия по сравнению с другими методами (статистикой, нейронными сетями).
Система работает по этапам построения. Нужно только задать соответствующие вопросы, а именно, выбрать критерии атрибутов. По ним разбивается каждый этап, происходит обучение и отсечение ветвей.
Чтобы правильно произвести разбивку, вычисляются правильные теоретико-информационные критерии. Для этого используется формула:
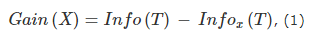
где Info(T) - энтропия множества T, а
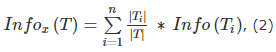
Также подготавливается статистический критерий по индексу Джини. Он более точно помогает распределить классы, используя следующую формулу:
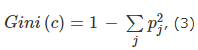
где c - текущий узел, а pj - вероятность класса j в узле c.
Достаточно просто загрузить файлы в нашу систему, чтобы получить результат и рассчитать различные данные.
После потребуется нажать «Далее», и перед вами появится новая таблица. Может понадобиться очистка выборки, в процессе которой оператор вносит какие-либо собственные критерии или те, что предложены системой. Все зависит от того, каким должен быть результат.
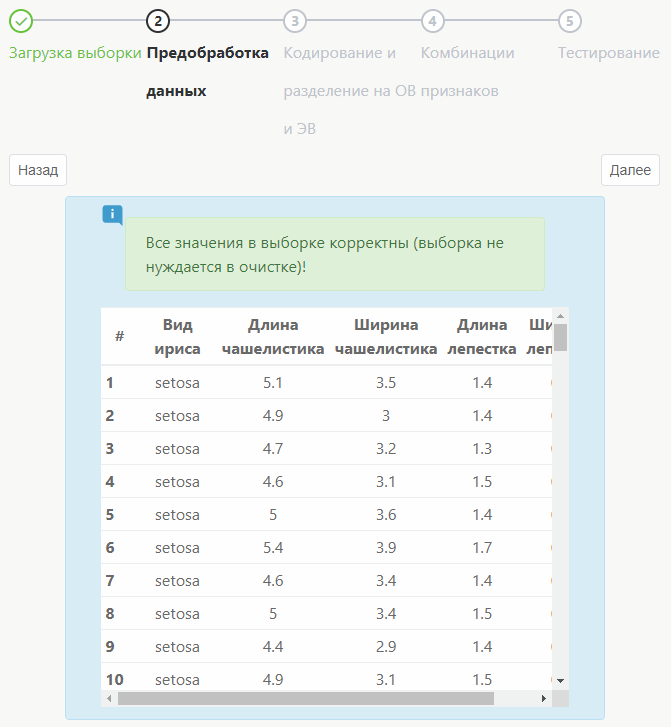
После этого будет выполняться кодирование и разделение кодированной выборки на обучающую и тестовую (экзаменационную). Оператор может установить нужное количество кластеров, тип кодирования и условие разделения.
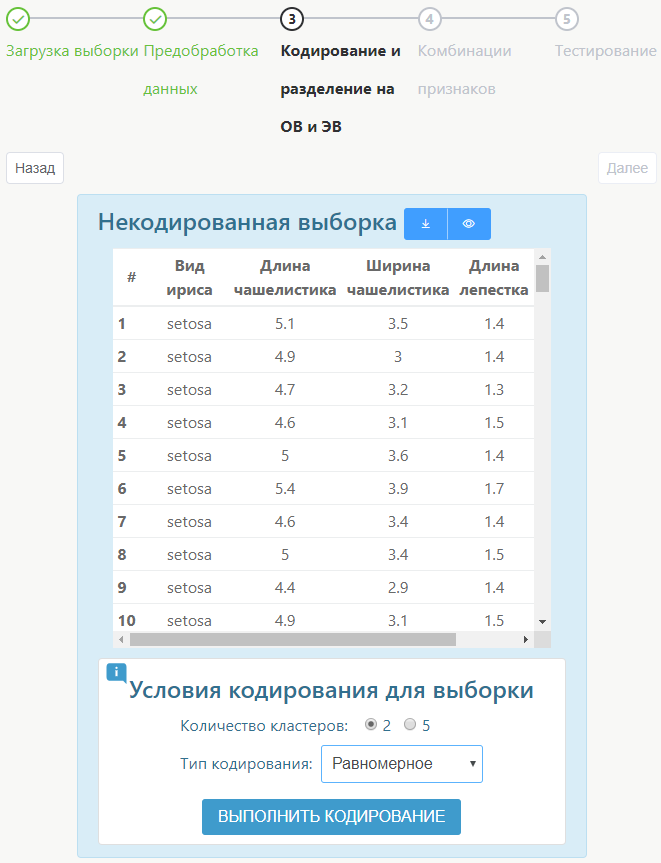
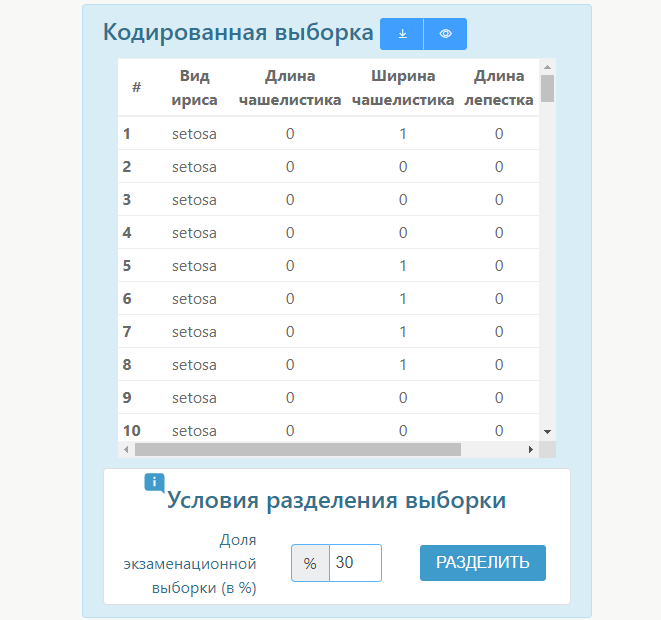
После этого потребуется перейти к комбинации признаков. Здесь также можно выбрать различные параметры, после завершения кодирования система позволяет взглянуть более подробно на каждый результат при необходимости.
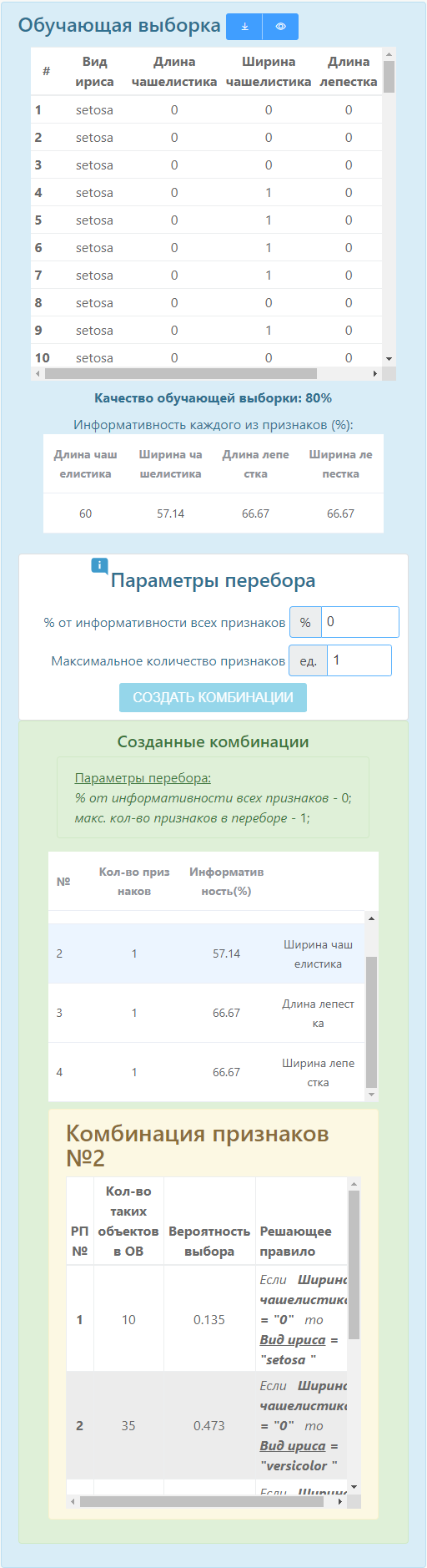
В заключение можно приступать к тестированию. Программа оповестит обо всех особенностях, приведет диагностику и выдаст возможные результаты в процентном соотношении.
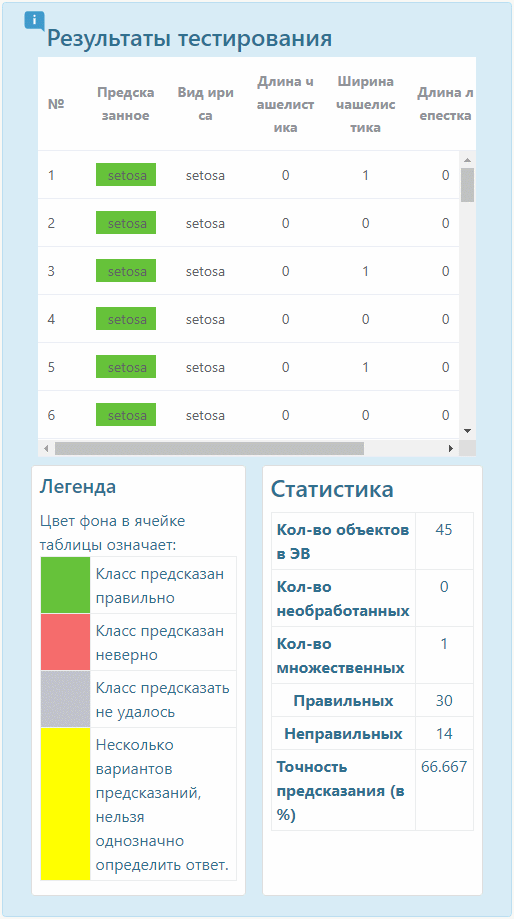
В течение всей работы можно визуализировать или сохранять выборку, чтобы более подробно просмотреть нужные данные. Наш сервис предоставляет необходимые элементы для процесса визуализации.